

前文讨论了实现可靠数据传输的核心机制,但最后的实现结果性能实在太差,没法用。TCP协议在实现了核心机制的情况下,寻求提高性能的办法,最后才使可靠数据传输最终落地,我们来看看TCP协议都做了啥。
流量控制 --滑动窗口
前文的Rdt3.0性能差的最主要原因就是等待的过程,每发送一个包就需要等待响应。
此时就可以考虑使用一个流水线机制,即允许发送方在没有接收到响应的时候可以发送多个包,减少等待时间。为此就需要引入以下措施:
- 此时需要检查的包就不止当前包和上一个包了,于是需要对序列号进行拓展。
- 为了保证实现重传,发送方需要缓存所有未收到确认的包。
- 为了保证包的有序,接收方也需要缓存,对包进行排序之后才提交给上层
- 需要引入新的重传机制
前三项好理解,发送方给每个数据包都打上序列号,接收方接收到之后,返回ACK,并带上目前成功接收到的包的序列号。重点在于重传机制。
1.0版本
由于引入了滑动窗口,比如序列号为2的包丢失,发送方仍然继续发送序号3、4、5的包。接收方接收到了之后,返回的ACK序号仍然是2。 但发送方已经发到5了。此时就可以简单的认为仅仅成功发送了序号为2的包,重新从2号开始重传。
这无疑是效率很低的,成功收到的3、4、5号包都被丢弃了。于是对其做了部分改进
1.1版本
假设中间的2号包只是因为网络延迟而没有收到,那我们就用一个定时器来解决,只有当超时之后,才最终认为2号包丢失,需要重传。
这已经解决了部分问题,提高了效率,但每次都要等待超时,还有没有更快的办法?
2.0版本 --TCP快速重传
我们其实可以利用包丢弃机制,当接收到连续的n次重复ACK之后,立即重传这个包。这个例子里,服务器立即重传了2号包,并且客户端正确接收到了,回复了ACK=6,服务器就知道了序号5的包也已经发送到了,可以继续发送后面的包。而那个延迟的包在之后到达,也只会让客户端发送一个确认包。之后作为重复的包被丢弃,不会造成影响。
此时通过对网络延迟的处理减少了包的重传,但一旦要重传,就要把从丢失包的序号开始,全部传一遍。还能不能进一步优化?
3.0版本 -- SACK( Selective Acknowledgment 选择性确认)
单纯的ACK序号不能让发送方知道到底有哪些包已经成果接收到了。于是需要在ACK报文里添加额外的信息:
TCP 头部「选项」字段里加一个 SACK 的东西,它可以将缓存的地图发送给发送方,这样发送方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。
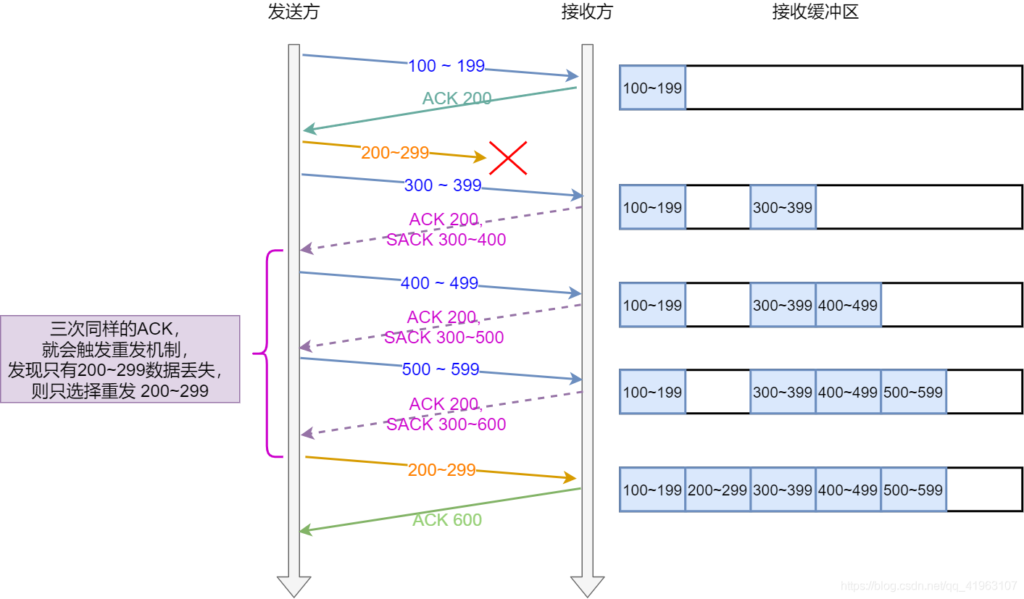
图中发送方收到了三个ACK=200,触发快速重传;但从SACK里得知300-599的包都被成功接收,只需要重传200-299即可。
拥塞控制
前面的滑动窗口机制很好地解决了效率问题,也探讨了新机制下的重传机制,但实际的网络环境比这复杂的多。主要考虑以下两点:
- 数据处理的速度有上限 -> 接收端的数据处理速度太慢导致缓冲区满了,后续的包被丢弃。
- 网络的承载容量有上限 -> 网络中过多的数据包引起网络延时,导致更多的包无法被接收,而满天飞的重传包加剧了网络的拥塞。
1.0版本 -- 根据接收窗口进行流量控制
首先需要解决数据处理速度上限的问题,当接收方缓冲区满的时候,就不要继续发了,再发也没用。所以可以在ACK报文里添加上接收端的接收窗口剩余大小。发送方动态调节发送窗口,不发送超过接收窗口长度的报文。当返回的窗口大小为0的时候就直接停止发送。之后等待窗口大小改变的响应报文。
或者是发送方迟迟收不到响应报文,发送窗口满了就停止发送,之后等待响应。
但是这会导致一种情况, 窗口大小为1的时候立即就发送响应报文,之后发完一个包,又停住了。这就又回到了 停止--等待。效率又降低了。又或者是窗口大小改变的响应报文丢失了,发送方一直不知道啥时候才能发。
1.1版本 -- 引入定时窗口询问
既然是解决丢包问题,就又要引入定时器了。发送方定期发送大小为1字节的窗口询问包,接收方可以选择回应窗口大小。这里接收方可以等待窗口大小大于某个阈值之后才允许发送,避免陷入 停止--等待 。
2.0版本 -- 引入动态超时控制
我们知道,一旦超时,那么就需要进行重传,这会增加网络负担。但如果设定的超时时间太长,又会引起长时间的等待。所以tcp会在发包时记录一次时间,收到对于的ack包的时候计算从发包到响应的时间差。经过采样算法,得出RTT,根据RTT动态设定RTO即超时时间。避免过多的重传和过长时间的等待。
动态超时控制只能用在网络波动平缓的时候,如果在短时间内网络剧烈波动,计算出来的RTO就不适用了,可能出现大量的超时重传,进一步恶化网络环境。所以还需要其他的控制手段。
3.0版本 -- 引入拥塞控制算法
拥塞控制算法主要是针对发送窗口进行动态调整,目前有多种拥塞控制算法。首先介绍最为传统的算法--基于丢包的拥塞控制算法:TCP Reno
先看过程图
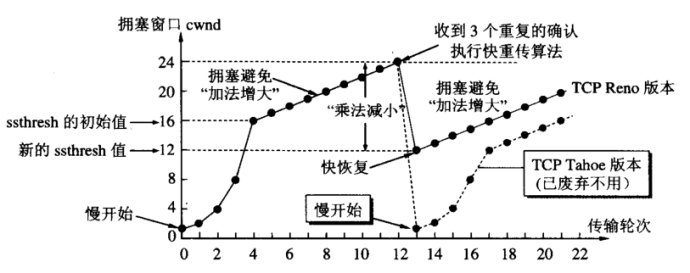
Reno将拥塞控制的过程分为四个阶段:慢启动、拥塞避免、快重传和快恢复。
首先需要设定一个拥塞避免阈值,这里为16。
慢启动阶段,一开始的发送窗口大小只有1,由于此时发送速率慢,所以叫慢开始。
之后每接收到一次ACK报文,就把发送窗口*2,快速增加窗口的大小。
当达到设定的拥塞避免阈值的时候,开始进行拥塞避免。此时发送窗口线性增大,一点一点探测网络容量。
当出现丢包情况,这里引入了快速重传,所以是收到三个重复的确认信息之后直接重传,并进入快恢复阶段。
快恢复阶段,将当前的拥塞窗口缩小一半,并把拥塞避免阈值也设为缩小一半后的值。
之后就又开始进行拥塞避免...不断重复。
有关拥塞控制算法的拓展知识
Cubic算法
目前Linux底层使用的还是基于丢包的拥塞控制算法,但相较传统的Reno算法做了部分改进。
由于Reno算法的拥塞窗口增长依靠接收到的ACK包,当网络时延较大时,拥塞窗口的增长就会变得缓慢。
目前Linux内核使用了Cubic算法,使用了一个立方函数来作为拥塞窗口增长因子:
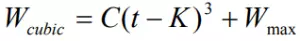
其中W就是拥塞窗口,C是调整因子,是一个常数,t是从上一次缩小拥塞窗口经过的时间,Wmax 是上一次发生拥塞时的窗口大小。
其中参数K的算法如下:
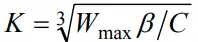
其中β是乘法减小因子。用于控制丢包后快恢复的起点。
直接看这种算法下拥塞窗口的增长曲线:
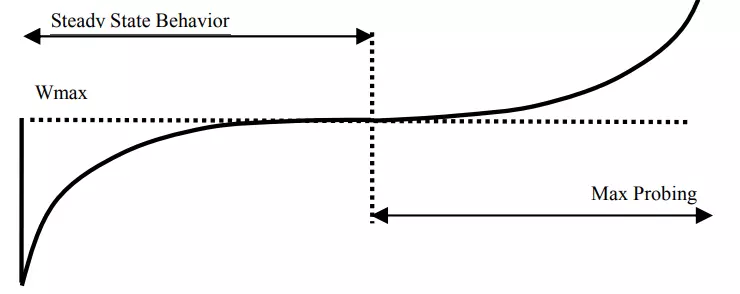
前半段对应慢启动,增长较快,接近Wmax的时候增长减缓,此时也最容易出现拥塞丢包。一段时间后增长加快,用于尽快达到最大带宽。
可以看出这种算法进一步提高了带宽的利用率,其拥塞窗口的增长与RTT无关。但由于其基于丢包,无法判断某个包是因为损坏还是网络拥塞,会直接降低拥塞窗口,但这毕竟是小概率事件,影响不大。
所以这种算法适用于高带宽、低丢包率的网络,对于网络的延时不敏感。
但这种算法对于拥塞窗口的控制属于激进型的,会尽可能利用所有的带宽。考虑到接收方的处理速度,可能会出现缓冲区膨胀(Bufferbloat),导致很多时候数据包是在缓冲区排队,增加了网络的总体时延。
BBR算法
这是由谷歌推出的基于拥塞的拥塞控制算法,即其更贴近拥塞的本质:网络的总体容量。
BBR 算法周期性地探测网络的容量,交替测量一段时间内的带宽极大值和时延极小值,将其乘积作为作为拥塞窗口大小(交替测量的原因是极大带宽和极小时延不可能同时得到,带宽极大时网络被填满造成排队,时延必然极大,时延极小时需要数据包不被排队直接转发,带宽必然极小),使得拥塞窗口始的值始终与网络的容量保持一致。
由于 BBR 的拥塞窗口是精确测量出来的,不会无限的增加拥塞窗口,也就不会将网络设备的缓冲区填满,避免了出现 Bufferbloat 问题,使得时延大大降低。如图所示,网络缓冲区被填满时时延为 250ms,Cubic 算法会继续增加拥塞窗口,使得时延持续增加到 500ms 并出现丢包,整个过程 Cubic 一直处于高时延状态,而 BBR 由于不会填满网络缓冲区,时延一直处于较低状态。
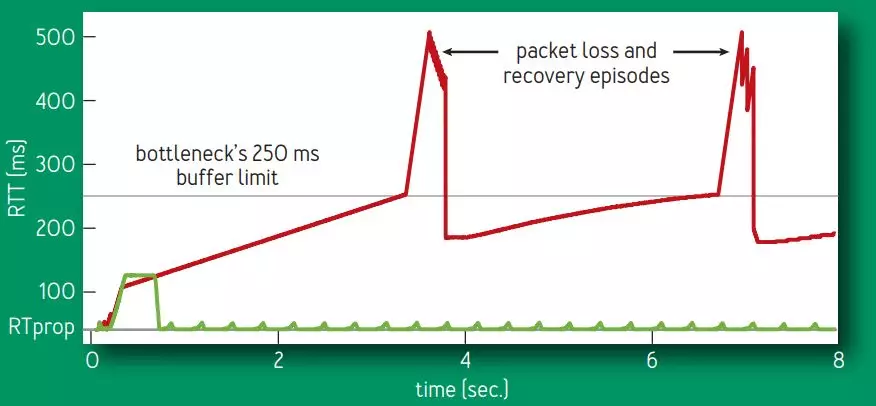
由于 BBR 算法不将丢包作为拥塞信号,所以在丢包率较高的网络中,BBR 依然有极高的吞吐量,即BBR可以分辨一个丢包是由于拥塞还是损坏了!此外BBR在控制拥塞窗口的同时还会给出一个pacing rate,指示数据包的发送速率。防止瞬时发送大量数据导致网络剧烈波动。
目前BBR算法也合并到了Linux底层的拥塞控制算法中,并且对TCP的实现做出了更改:即将流量控制和拥塞控制分开来。流量控制决定发什么,是重传还是接着发;而拥塞控制决定怎么发,一次发多少,间隔多长时间发。这也是本文组织的结构,将流量控制和拥塞控制分开讨论。
更多关于bbr的细节可以看这个:https://www.cnblogs.com/jkc626/p/13702033.html
拥塞控制算法分类总览
- 基于丢包的拥塞控制:将丢包视为出现拥塞,采取缓慢探测的方式,逐渐增大拥塞窗口,当出现丢包时,将拥塞窗口减小,如 Reno、Cubic 等。
- 基于时延的拥塞控制:将时延增加视为出现拥塞,延时增加时增大拥塞窗口,延时减小时减小拥塞窗口,如 Vegas、FastTCP 等。
- 基于链路容量的拥塞控制:实时测量网络带宽和时延,认为网络上报文总量大于带宽时延乘积时出现了拥塞,如 BBR。
- 基于学习的拥塞控制:没有特定的拥塞信号,而是借助评价函数,基于训练数据,使用机器学习的方法形成一个控制策略,如 Remy。
叨叨几句... NOTHING